

NEWS & EVENTS
Insights on the Latest Trends and Evolving Market Dynamics
Current location:
Home > News > Company News > Gooxi 8-GPU Server Sets New Benchmark, Boosting AI Training and Inference Performance by 35%Gooxi 8-GPU Server Sets New Benchmark, Boosting AI Training and Inference Performance by 35%
Game-Changing Performance: A 35% Boost in AI Training and Inference! Gooxi has achieved a groundbreaking 35% increase in the NCCL (NVIDIA Collective Communications Library) performance across its entire 8-GPU server lineup. This full-stack optimization results in NCCL bandwidth hitting 26GB, with significant leaps in both AI inference efficiency and energy efficiency. Real-world tests on large models such as DeepSeek and Llama2/3 show that Gooxi’s servers can deliver up to a 35% performance boost for billion-parameter models, while simultaneously reducing TCO (Total Cost of Ownership) by nearly 30%. This sets a new performance benchmark for domestic AI servers and positions Gooxi as a key enabler for large model inference at scale.
In AI training and inference, the efficiency of communication between multiple GPUs is a major hurdle that limits computational power. Gooxi’s engineering team tackled this challenge head-on with a complete overhaul of the NCCL protocol, hardware topology, and data flow scheduling. By optimizing dynamic load balancing and reducing communication latency, Gooxi has effectively eliminated the “communication wall” that often hampers distributed training at scale. This innovation has resulted in a 35% improvement in both training and inference for models with billions of parameters, accelerating the development of massive models like DeepSeek.
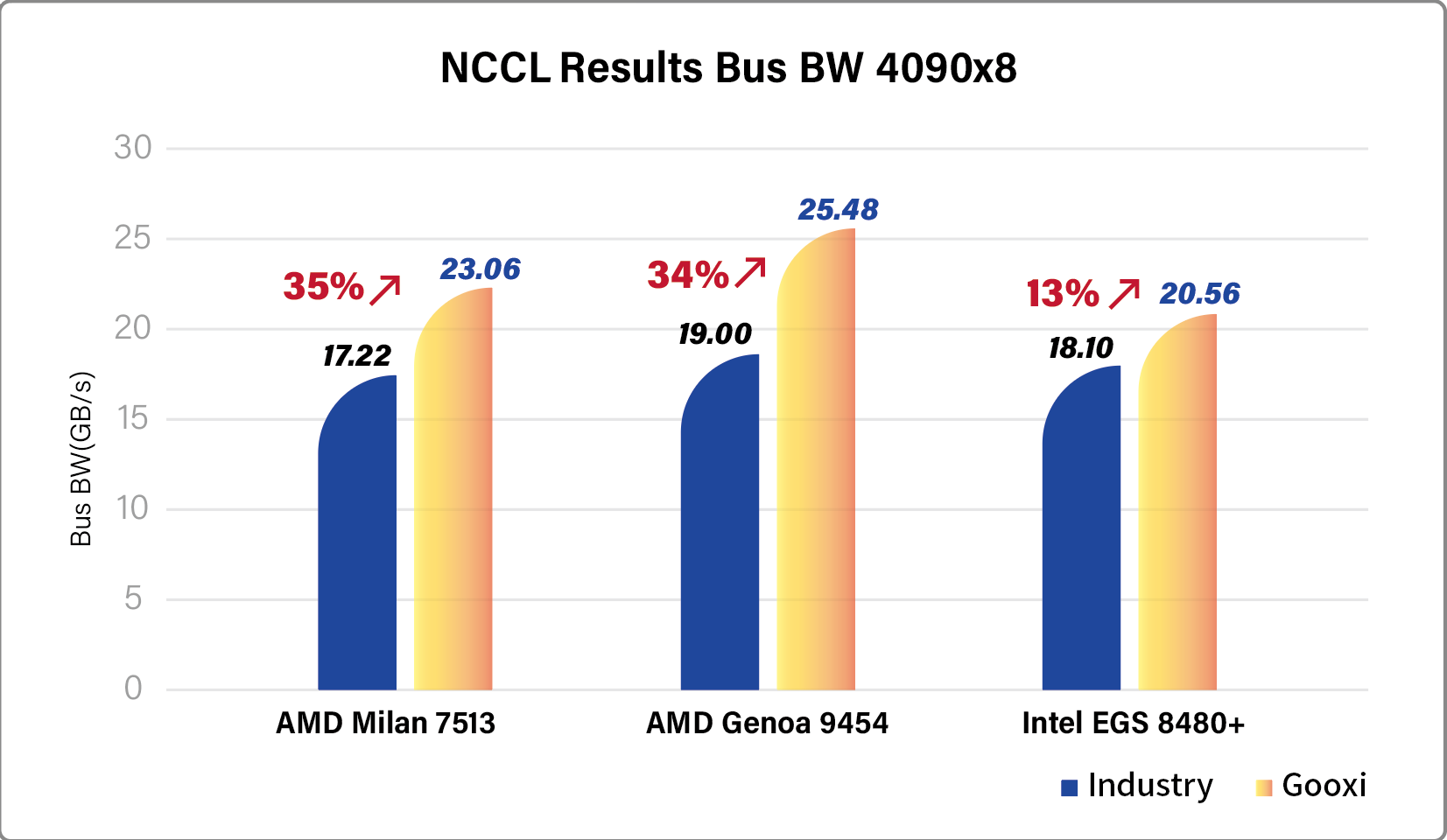
To showcase the real-world value of these innovations, Gooxi ran extensive tests using the DeepSeek model. The results speak for themselves:
· Inference throughput: Gooxi’s servers achieved a 35% boost in the number of tokens processed per second, pushing inference speeds to near-millisecond response times.
· Energy efficiency: A 35% improvement in energy efficiency, thanks to smart power management algorithms, resulted in more than a one-third reduction in energy consumption per inference task—helping companies make the transition to green computing.
· Long-context advantages: In DeepSeek’s long-text generation and complex reasoning tasks, Gooxi’s optimizations reduced communication latency, improving model output coherence by 15%, which significantly enhanced the user experience.
· TCO reduction: The performance improvements translate directly into cost savings. Companies can reduce TCO by up to 30%, allowing them to deploy 30% more inference nodes with the same budget, cutting down large model inference costs and improving AI application ROI by more than 2 times.

Pre-optimization vs. Post-optimization
As AI models scale toward trillion-parameter sizes, the challenge of compute costs and efficiency becomes increasingly critical. Gooxi’s breakthrough addresses this issue head-on, offering a 30% reduction in TCO that allows businesses to deploy significantly more compute power within the same budget. This move also drives model inference costs down to a per-token basis, saving millions in operational expenses annually and offering a 2 times boost in AI application ROI.

Gooxi’s achievements pave the way for a more accessible AI landscape, making high-performance AI more affordable and scalable for businesses of all sizes. This is a crucial step toward the widespread adoption of AI, unlocking new opportunities for AI-driven innovations across industries and building a solid foundation for AGI.
Related recommendations
Learn more news
Leading Provider of Server Solutions


YouTube

