

NEWS & EVENTS
Insights on the Latest Trends and Evolving Market Dynamics
Current location:
Home > News > Company News > Exploring the Mechanics of Inter-GPU Communication with NCCLIn the AI industry, training large-scale models is often likened to “alchemy”—a metaphor that has quickly become common parlance. Ideally, large-scale model training should be as straightforward as combining a fleet of identical GPUs, like the H100s, into clusters of thousands, distributing preprocessed data across GPUs to run through the model, and refining the model based on the results.
However, the reality is often more complex. Budget constraints, supply chain limitations, and variations in GPU performance make it challenging to assemble homogeneous clusters. With heterogeneous GPUs, the question becomes: how do we maximize computational efficiency while overcoming memory and performance bottlenecks? And how can we unlock the potential of heterogeneous clusters?

Typically, large-model training follows these steps:
In a single server, NVIDIA GPUs rely on NVLink and NVSwitch to ensure fast data transfer and synchronization across GPUs. For GPUs across different servers, interconnects like InfiniBand (IB) or RoCE come into play. With external communication resolved, NVIDIA’s NCCL (NVIDIA Collective Communications Library) comes into play for high-speed inter-GPU communication, enabling efficient data synchronization to facilitate training.
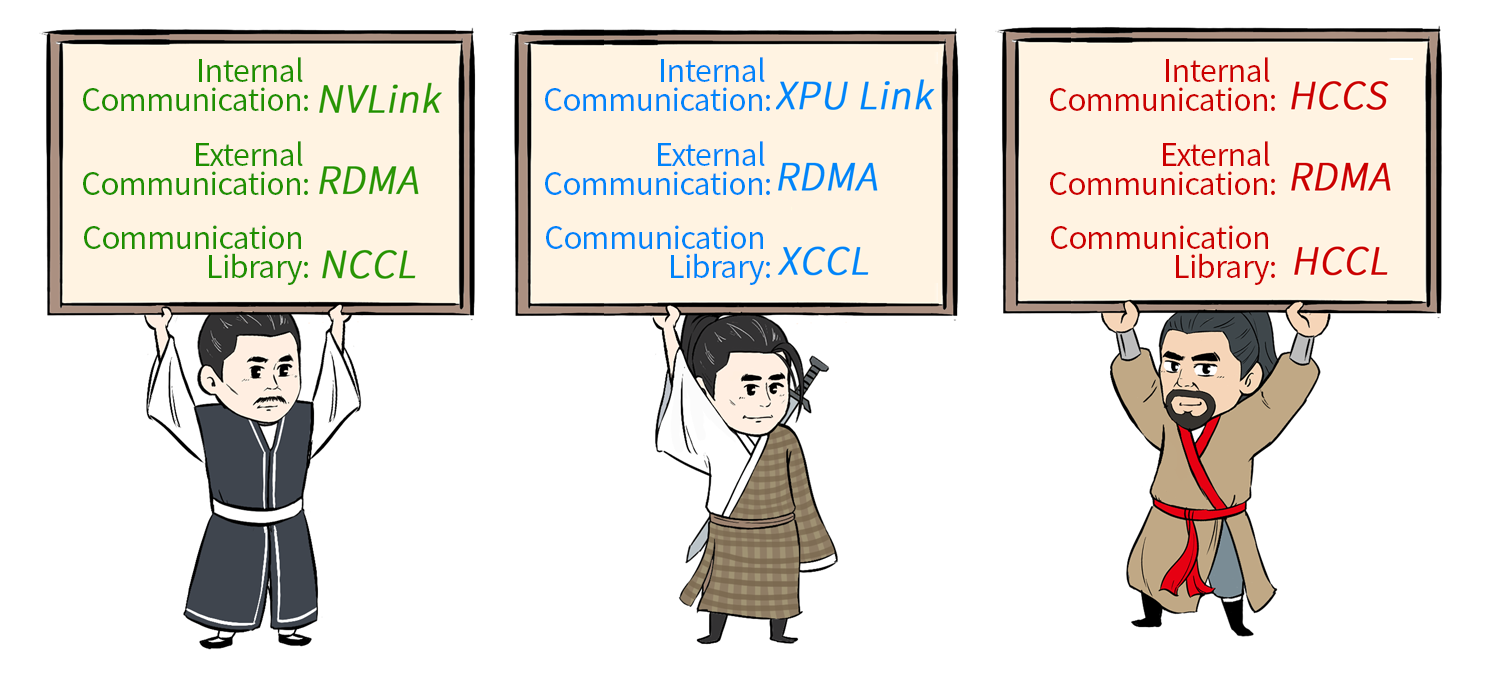
The NVIDIA Collective Communications Library (NCCL) has become an essential tool for addressing the communication challenges specific to deep learning. While MPI (Message Passing Interface) is commonly used for CPU-based applications, NCCL is the go-to for multi-GPU distributed training and inference on NVIDIA hardware.
Simply put, NCCL provides an interface that enables efficient inter-GPU communication without requiring users to manage the intricate details of node-to-node connectivity. By abstracting these complexities, NCCL allows seamless communication between GPUs with minimal user intervention.
As a performance metric for GPU server model training, NCCL facilitates single-machine, multi-GPU, and multi-machine, multi-GPU communication, streamlining communication both within and across nodes. Supporting various interconnect technologies like PCIe, NVLink, InfiniBand Verbs, and IP sockets, NCCL is compatible with most multi-GPU parallelization models, enhancing data transfer speeds across GPUs.
NCCL offers a range of optimized communication primitives—such as AllReduce, Broadcast, Reduce, AllGather, and ReduceScatter—and peer-to-peer communication capabilities. These enable developers to synchronize and transfer data efficiently across multiple GPUs, which is critical for large-model training. NCCL is integrated into popular deep learning frameworks, including PyTorch, TensorFlow, Cafe2, Chainer, and MxNet, to accelerate multi-GPU training across nodes. Available as part of the NVIDIA HPC SDK or as standalone packages for Ubuntu and Red Hat, NCCL is accessible for diverse system configurations.
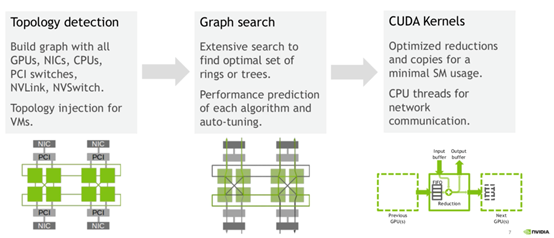
A primary feature of NCCL is its ability to detect the network topology of compute nodes and dynamically select the optimal communication method. Each compute node may have unique configurations, from different network cards (such as InfiniBand or RoCE) to various GPU interconnects (NVLink or PCIe). For optimal performance, NCCL identifies the network, CPU, and GPU characteristics of each compute node and uses tuning tools to select the best communication method.
Through these optimizations, NCCL achieves low latency and high bandwidth—an essential combination for deep learning models requiring frequent data exchange.
Gooxi’s latest AMD Milan dual-socket 4U 8-GPU AI server, powered by AMD EPYC 7003/7002 processors with direct CPU-to-GPU communication, is designed to balance performance and cost. With 13 PCIe expansion slots and the capacity to support 8 full-length, full-height, dual-width GPUs, the system can achieve NCCL bandwidths of up to 17.22 GB/s. This robust setup provides ample compute power for training complex AI models on large datasets, enabling massive parallel computing and significantly reducing training times for large models.

By pushing the boundaries of performance and efficiency in model training, Gooxi’s server offers strong computational support for complex AI tasks, making it an ideal choice for high-performance AI infrastructure. With the power of NCCL, Gooxi’s 4U 8-GPU server streamlines the process, empowering AI practitioners to train larger models faster and more efficiently.
Related recommendations
Learn more news
Leading Provider of Server Solutions


YouTube

